How building materials buyers search now — and why your catalog isn't the answer
Building materials buyers now ask AI before they call a distributor. See why thin, ERP-style catalog data gets skipped and what machine-readable specs look like.
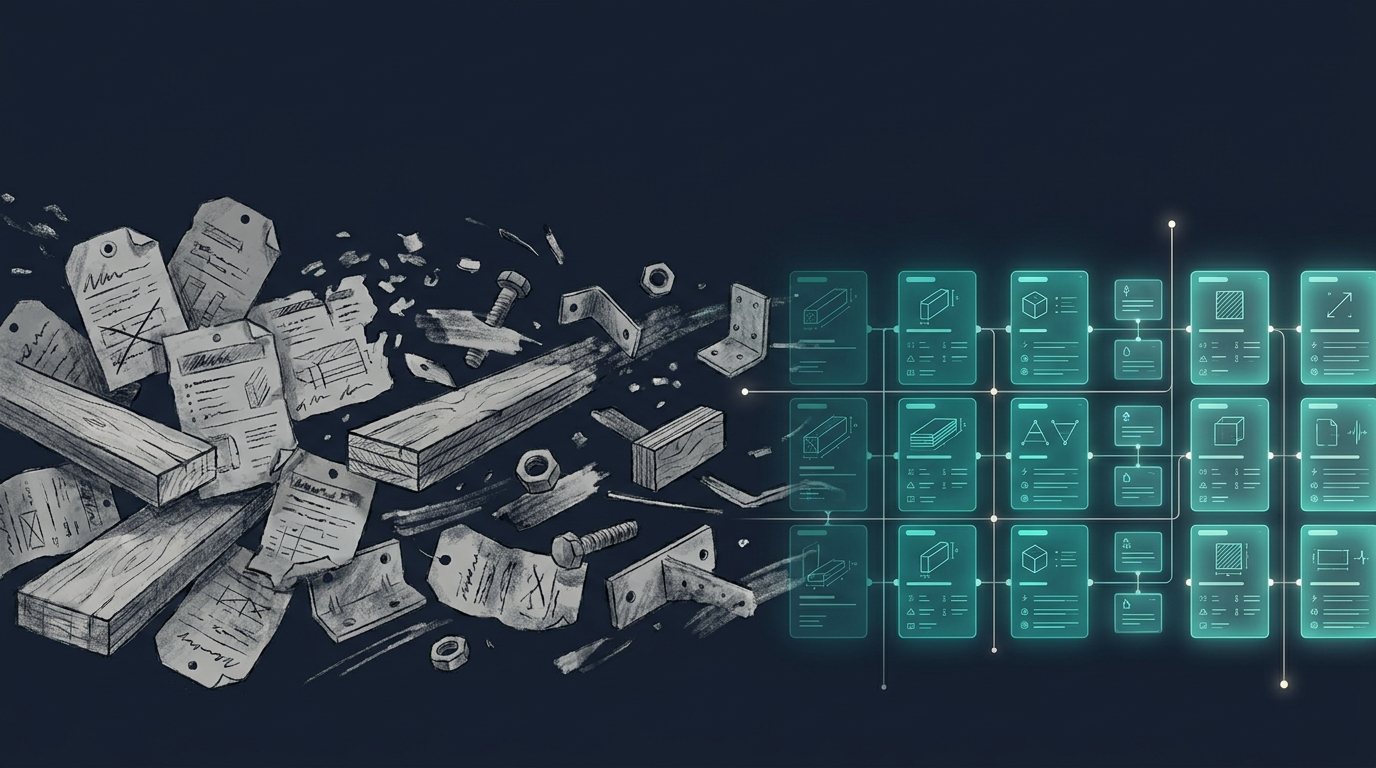
A GC's estimator used to start a materials search with a phone call or a distributor's catalog PDF. Increasingly, they start with a prompt. Machine Relations' 2026 buyer research puts 94% of B2B buyers using generative AI somewhere in their purchase process, with more of them naming AI tools as their most meaningful research source than vendor websites, product experts, or reps combined (Machine Relations, 2026). A separate survey of over 350 B2B buyers found one in four now prefer AI chatbots to conventional search when researching suppliers, and two-thirds rely on them as much as Google (Digital Commerce 360, 2025).
For a building materials distributor, that shift lands on a specific weak point: the product data itself.
The shortlist forms before your rep gets the call
When a buyer asks an answer engine to compare R-13 vs R-15 fiberglass batt insulation for a 2x4 wall in climate zone 4, or find a distributor stocking Type X fire-rated drywall in 5/8 inch thickness with same-day will-call, the model isn't browsing your site live. It's reasoning over whatever structured, citable text it can already parse, and it moves on quickly when a product page doesn't answer the question. There's no estimator on the other end to say "let me check the spec sheet." An AI agent comparing suppliers just drops the row that doesn't parse and keeps the one that does.
That's a rough fit for an industry whose catalogs were built for ERPs, not readers. Building materials data has always been notoriously inconsistent across manufacturers and distributors: one supplier lists a 2x6x8 PT lumber, another lists TREATED 2X6-8FT, and R-value, fire rating, or coverage-per-unit show up in a linked spec-sheet PDF instead of on the page. A contractor might dig through that. A model comparing ten distributors' attributes side by side just skips the one it can't read.
Why ERP-style feeds go invisible to LLMs
| ERP-style feed | Machine-readable product content |
|---|---|
SKU: 88213, Desc: INSUL BATT R13 15x93 | Full name, R-value, thickness, width, length, coverage area, fire/smoke rating |
| Inconsistent units and abbreviations per supplier | Normalized dimensions and attribute names across the whole catalog |
| Spec buried in a linked PDF datasheet | Specs as structured, queryable attributes on the page itself |
| No application or compatibility context | Use-case, code compliance, and comparison context an answer engine can quote |
A part number and a linked datasheet might satisfy a yard's inventory system. It gives an AI answer engine nothing to cite back to a buyer.
Before and after: a fire-rated drywall SKU
Raw feed description: GYP BD 5/8 TYPE X 4X8 with a PDF spec sheet link and no other page attributes.
Enriched attribute table:
| Attribute | Value |
|---|---|
| Product type | Type X fire-rated gypsum board |
| Thickness | 5/8 in |
| Panel size | 4 ft x 8 ft |
| Fire rating | 1-hour rated assembly (UL-listed core) |
| Edge type | Tapered |
| Typical application | Fire-rated wall and ceiling assemblies, commercial and multifamily |
| Compliance | Meets ASTM C1396 |
The second version is what a model can actually answer a code-compliance question with. The first is a warehouse label.
Ask an answer engine: try it yourself
Type this into ChatGPT or Perplexity: Which distributor stocks 5/8 inch Type X drywall rated for a 1-hour wall assembly with same-day pickup? Watch which names come back, and which don't. Structured data isn't a nice-to-have here, it's the difference between showing up and not: pages with clear headings and rich structured markup see roughly 2.8x higher citation rates from AI answer engines than unstructured pages, according to AirOps' analysis of the current AI search landscape (AirOps, 2026 State of AI Search). If your product page only exposes a part number and a PDF link, you're not in that answer, regardless of how much inventory is actually sitting in your yard.
What changes, and what doesn't
This isn't an argument for ripping out your ERP or PIM. Distributors run on those systems for inventory, pricing, and order flow, and none of that needs to move. The gap is between what those systems store and what a buyer, human or AI, needs to read: complete, normalized, quality-scored attributes, in the vocabulary contractors and models actually search in, kept current as manufacturers update specs and SKUs turn over. Manual enrichment at that level typically runs 30-45 minutes per SKU when a team does it by hand, which is why most catalogs never get past the ERP description in the first place.
Anglera is built for that specific gap. Your PIM or ERP keeps storing the data; Anglera scores, gap-fills, and enriches it on top, plugging into Akeneo, Salsify, inriver, Stibo, Syndigo, Pimcore, Informatica, or a flat file if that's what a distributor is running today. Values are pulled from real supplier documentation and quality-scored, not invented, and a distributor can have a working, machine-readable feed live in 30 days or less rather than a multi-year systems project. The buyers asking answer engines about R-value and fire ratings aren't waiting for that project to finish.
The channel is being reranked right now, one prompt at a time. Catalogs that read clearly, to people and to models, get cited. The rest get skipped without anyone noticing until the quotes stop coming in.
